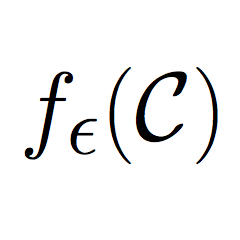
“The advancement and perfection of mathematics are intimately connected with the prosperity of the State.”
Napoléon Bonaparte — Correspondance de Napoléon, t. 24
Overview
My research revolves around the area of nonlinear optimization, a subfield of applied mathematics, and its applications in various disciplines, such as operations research, computer science, and statistics. The majority of my work involves designing algorithms, proving convergence theories, and developing software to solve problems of the form
$$\begin{aligned} \min_{x\in\mathbb{R}^n} &\ \ f(x) \\ \text{s.t.} &\ \ e(x) = 0 \\ &\ \ c(x) \leq 0 \end{aligned}$$
where \(f : \mathbb{R}^n \to \mathbb{R}\), \(e : \mathbb{R}^n \to \mathbb{R}^p\), and \(c : \mathbb{R}^n \to \mathbb{R}^q\) are continuously differentiable, or at least locally Lipschitz over \(\mathbb{R}^n\) and continuously differentiable almost everywhere in \(\mathbb{R}^n\). While my research focuses on solving problems of this form, the numerical methods that I develop may be utilized within any algorithm that requires the solution of nonlinear optimization subproblems, and often the methods that I develop are designed with such algorithms in mind.
My research is supported by the following federal grants.
- National Science Foundation CCF-2139735, “Collaborative Research: AF: Small: A Unified Framework for Analyzing Adaptive Stochastic Optimization Methods Based on Probabilistic Oracles,” PI, January 2022 — December 2024
- Office of Naval Research N00014-21-1-2532, “Next-Generation Algorithms for Stochastic Optimization with Constraints,” PI, May 2021 — May 2024
- National Science Foundation DMS-2012243, “An Accelerated Decomposition Framework for Structured Sparse Optimization,” co-PI, July 2020 — June 2024
My research was previously supported by the following federal grants.
- National Science Foundation CCF-1740796, “Collaborative Research: TRIPODS Institute for Optimization and Learning,” PI, January 2018 — July 2023
- National Science Foundation CCF-2008484, “Collaborative Research: AF: Small: Adaptive Optimization of Stochastic and Noisy Functions,” PI, October 2020 — May 2023
- Department of Energy DE-AR0001073, “Hybrid Interior-Point / Active-Set PSCOPF Algorithms Exploiting Power System Characteristics,” PI, December 2018 — July 2020, renewal August 2020 — July 2022
- National Science Foundation CCF-1618717, “AF: Small: New Classes of Optimization Methods for Nonconvex Large Scale Machine Learning Models,” co-PI, September 2016 — August 2020
- National Science Foundation CMMI-1400164, “GOALI: Optimizing the Design of Ocean Wave Energy Farms,” Senior Personnel, June 2014 — May 2019
- Department of Energy DE-SC0010615, (Early Career Award) “Fast, Dynamic, and Scalable Algorithms for Large-Scale Constrained Optimization,” PI, July 2013 — June 2018
- National Science Foundation DMS-1319356, “Randomized Models for Nonlinear Optimization: Theoretical Foundations and Practical Numerical Methods,” co-PI, September 2013 — August 2017
- National Science Foundation DMS-1016291, “Nonlinear Optimization Algorithms for Large-Scale and Nonsmooth Applications,” PI, July 2010 — December 2013
Specific topics in which I am interested are listed below. Corresponding publications that relate to these and other categories are listed on my publications page.
Jump to…
- Large-scale Nonlinear Optimization
- Optimization Methods and Machine Learning
- Nonconvex, Nonsmooth Optimization
- Nonlinear Optimization Algorithms for Potentially Infeasible Problems
Large-scale Nonlinear Optimization
The majority of my research focuses on the design, analysis, and implementation of efficient and reliable algorithms for solving large-scale nonlinear optimization problems, i.e., those that involve thousands or millions of variables and constraints. The primary challenge in this line of work is to design numerical methods that can solve such problems while maintaining the global and fast local convergence guarantees offered by classical methods (that are only efficient when solving smaller-scale problems). Overall, my goals are to design algorithms with the following features:
- scalable step computation (for solving large-scale problems)
- effective handling of negative curvature (for handling nonconvexity)
- superlinear convergence in the primal-dual space (for high solution accuracy)
- asymptotic monotonicity in a merit function (for consistent improvement)
- effective active-set detection (for warm-starting)
The latter two features in the list above are especially important in latency-limited environments—i.e., real-time optimization—when one requires a good approximate solution quickly.
My collaborators and I have successfully developed a suite of algorithms for solving large-scale optimization problems that possess convergence guarantees on par with the best contemporary algorithms. Our algorithms may be considered of the “inexact Newton” variety, encompassing all of the well-known Augmented Lagrangian (AL), Sequential Quadratic Optimization (SQO), and Interior Point Method (IPM) frameworks; see the “Large-Scale Nonlinear Optimization” section on my publications page. One of the key ideas in all of this work is that, in order to have a scalable method capable of solving large-scale problems, one needs to design an algorithm in which the demands of the “outer” nonlinear solver are understood by the “inner” subproblem (typically a quadratic optimization problem or linear system) solver. By observing these demands, one can employ iterative optimization or linear algebra techniques and exploit inexact solves—as opposed to treating the subproblem solver as a “black-box” and/or employing direct factorization methods; see the “Large-Scale Quadratic/Subproblem Optimization” section on my publications page for my work on methods for solving subproblems arising in nonlinear optimization algorithms.
An important class of optimization problems for which our techniques are applicable are those where the constraints are defined by partial differential equations (PDEs). In such applications, the equality constraints often correspond to a discretized PDE and the inequality constraints may, e.g., represent bounds on sets of control and/or state variables. Example PDE-constrained optimization applications include shape optimization in fluid flows, weather forecasting, medical image registration, and earthquake modeling. As such problems involve so many variables and constraints, standard contemporary techniques are generally impractical or inapplicable. Our methods, however, are able to handle such problems efficiently through their use of iterative linear algebra techniques.
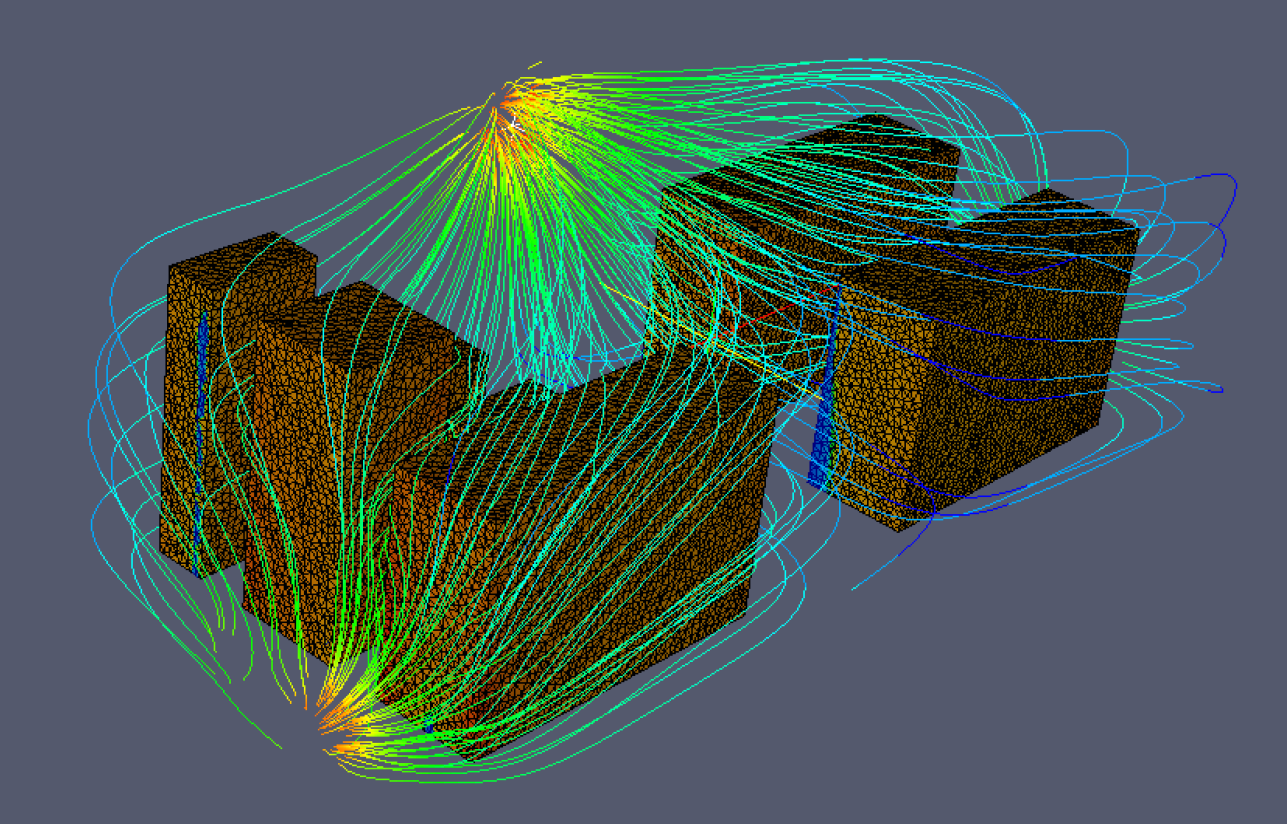
An example outcome of our work is an inexact interior-point method with inexact step computations implemented as part of the Ipopt software package. We have demonstrated the performance of this solver with the following test problem related to energy efficiency. Consider the problem to provide at least a certain air flow speed across the faces of machines in a server room in such a manner as to minimize work for the room’s air conditioners. Such a problem can be formulated as a PDE-constrained optimization problem. The constraints of the problem involve a discretized PDE modeling the air flow and bounds on the air speed along the faces of the obstacles in a three-dimensional representation of the server room. The objective is to minimize the air speed at the air conditioning units. A particular instance of this type of problem involving hundreds-of-thousands of variables and constraints was solved with our algorithm and the solution is illustrated below. Each iteration of the algorithm required under 9 minutes, a speed-up of over 75% compared to the default Ipopt algorithm, which required approximately 40 minutes per iteration. It is expected that the speed-up would be even more profound for larger problem sizes that more accurately represent the true infinite-dimensional problem.
Optimization Methods for Machine Learning
Some of the most exciting applications of nonlinear optimization algorithms in the past few years have been on solving problems arising in machine learning applications. These problems are extremely challenging to solve since they often involve large numbers of variables and computationally expensive functions, e.g., due to them being defined by an average of functions with each corresponding to a single data point in a huge dataset. Perhaps more importantly, these problems are challenging due to the fact that the problem being solved is only an approximation for the “true” learning problem that one aims to solve.
Most of the work that I have done in this area relates to algorithms for solving problems arising in supervised learning. Generally speaking, the setting of such a problem is that one aims to learn an appropriate mapping between inputs and outputs. For example, if the inputs are a set of images (e.g., of cats, dogs, birds, etc.), then one might want to learn a mapping that takes each input and turns it into a correct label for the image (e.g., “cat” or “dog”, etc.). The human brain learns and applies such “mappings” all the time, taking information through the optic nerve and deciding what one is seeing. As another example, if the inputs are a set of text documents, then one might want to learn a mapping that takes each document and determines whether or not the text discusses a certain topic (e.g., “sports”).
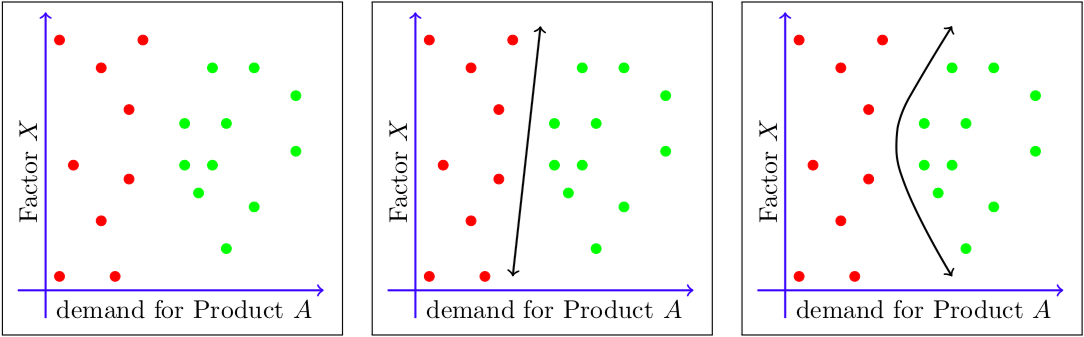
In the figure below, one aims to learn a function that helps a company determine whether “Product A” will be profitable or not in an upcoming quarter. Each data point represents the demand for the product and another factor (“Factor X”) in a previous quarter, where a red dot indicates that the product was not profitable in the subsequent quarter and a green dot indicates that it was profitable. Notice that, in this example, there are multiple functions that separate the known data points, but it is unknown which will lead to the best predictions on unknown data. This illustrates one of the challenges that arise when solving optimization problems for machine learning applications, namely, that one only has access to historical data in order to make predictions and/or determinations about future data.
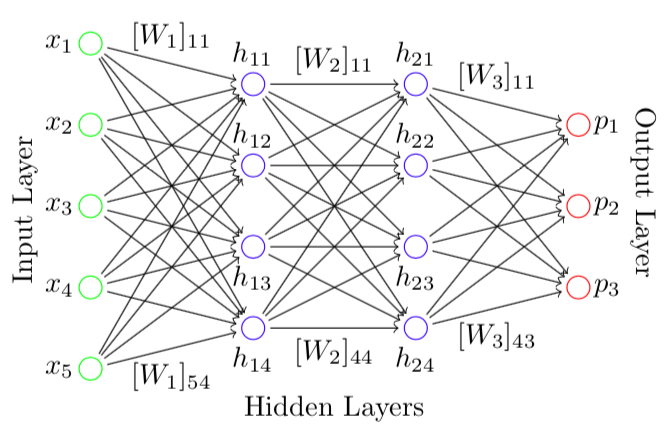
One of the most important decisions that one makes when attempting to solve a machine learning problem is the class of mappings over which one decides to optimize. Much of the excitement in machine learning nowadays relates choosing mappings that are defined by (deep) neural networks. Inspired by models of neurons in the human brain, neural networks can be viewed as computational graphs with which one takes an input and applies a series of linear and nonlinear transformations before arriving at an associated output. A loss function is then used to determine how much “loss” one incurs if the computed output differs (in some sense) from the known output. Optimization in this context means to find which transformations lead, on average, to the lowest amount of loss.
The optimization problems in this setting are large-scale and nonconvex, and it is easy to argue that the optimization process should avoid passes over the entire dataset if at all possible. A classical optimization method for solving such problems is the stochastic gradient method, also known as SG. (The method is sometimes referred to as “SGD”, where the “D” stands for “descent”, but I have strong feelings against this terminology since it is NOT a descent method!) Modern work in this area attempts to move beyond SG to design more sophisticated optimization algorithms for solving difficult problems as efficiently as possible. For further information, please see my review article with Leon Bottou and Jorge Nocedal.
Nonconvex, Nonsmooth Optimization
Numerous optimization problems of interest involve problem functions that are not continuously differentiable everywhere on \(\mathbb{R}^n\). Broad classes of optimization problems involve nonsmooth functions, including many in the areas of optimal control, eigenvalue optimization (with applications in robust stability of dynamical systems), and bilevel optimization. The challenges in solving nonsmooth optimization problems is that gradients of the problem functions are not defined everywhere, many have solutions at such points of nondifferentiability, and classical approaches for solving smooth problems often stall when applied to solve a nonsmooth problem.
Despite these challenges, nonsmoothness of the problem functions is not necessarily a major concern if the functions possess other agreeable structure(s), such as convexity. Indeed, numerical methods for solving convex (nonsmooth) optimization problems have been the subject of research for decades, and the well-known subgradient, proximal point, and bundle methods (to name a few) have been extremely successful in solving difficult problems. However, there are unfortunately few algorithms capable of reliably solving problems without such beneficial structure, especially when constraints are present. Thus, one of my research interests is the design of novel algorithms for solving nonconvex, nonsmooth optimization problems.
There are great opportunities for advancing the design of algorithms for nonconvex, nonsmooth optimization. The approaches that my collaborators and I have taken involve adapting a popular technique employed when solving smooth problems and merging it with randomized algorithms for capturing information about the nonsmoothness of the problem functions. In particular, the quasi-Newton method known as BFGS and its limited memory variant known as L-BFGS have demonstrated beneficial behavior when employed to solve nonsmooth problems, and, when tied to a randomized gradient sampling strategy, we developed sophisticated—yet relatively straightforward—algorithms that possess global convergence guarantees with probability one.
As an example problem on which my collaborators and I have tested our methods, consider a multi-plant controller design problem. In particular, for fixed sets of matrices \((A_i,B_i,C_i)\) for all \(i \in \{1,\dots,r+s\}\) representing linear dynamical systems with inputs and outputs and a matrix \(X\) representing the variable controller (common to all plants), consider the static output feedback plants defined by \(A_i + B_iXC_i\) for all \(i \in \{1,\dots,r+s\}\). The \(i\)th of these plants is considered stable in the presence of noise up to norm \(\epsilon>0\) if \(\rho_\epsilon(A_i + B_iXC_i) < 1\) where \(\rho_\epsilon\) is the \(\epsilon\)-pseudospectral radius function defined by
$$\begin{aligned} \rho_\epsilon(M) &:= \max\{|\gamma| : \gamma \in \sigma(M + E),\ \|E\| \leq \epsilon\} \\ \text{where}\ \ \sigma(M) &:= \{\gamma \in \mathbb{C} : \det(M – \gamma I) = 0\}. \end{aligned}$$
The function \(\rho_\epsilon\) is locally Lipschitz, but nonconvex and nonsmooth, making the problem to optimize it (in some sense) difficult even for a single plant. (With \(\epsilon=0\) one obtains the spectral radius function, which is even more difficult to handle as it is non-Lipschitz.) Given a small positive constant \(\delta \approx 0\) and a reference controller for which the set of systems indexed by \(i \in \{r+1,\dots,r+s\}\) are stable, the problem we consider is to minimize the \(\epsilon\)-pseudospectral radius of the “worst performing” plant while maintaining stability of the plants that are stable with respect to this reference controller:
$$\begin{aligned} \min_X &\ \max_{i\in\{1,\dots,r\}}\ \rho_\epsilon(A_i + B_iXC_i) \\ \text{s.t.} &\ \rho_\epsilon(A_i + B_iXC_i) \leq 1 – \delta\ \ \text{for all}\ \ i \in \{r+1,\dots,r+s\}. \end{aligned}$$
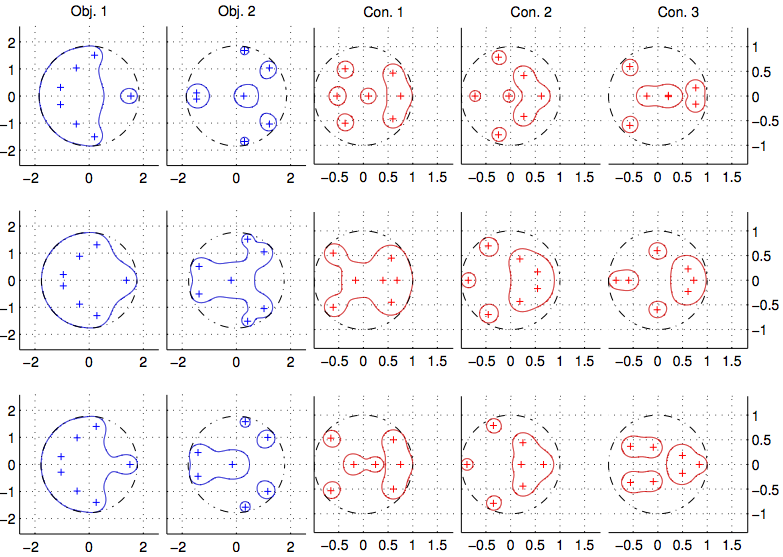
For a particular instance of this problem, the image below illustrates the solutions obtained by three algorithms, one corresponding to each row of plots. In each row, we illustrate the eigenvalues and \(\epsilon\)-pseudospectral radii of five plants, two of which are not stable (corresponding to Obj. 1 and Obj. 2) and three of which are stable (corresponding to Con. 1, Con. 2, and Con. 3) with respect to the reference controller. The best solutions were yielded by the latter two methods that we designed that combine algorithmic ideas from Sequential Quadratic Optimization (SQO), BFGS, and randomized gradient sampling.
Nonlinear Optimization Algorithms for Potentially Infeasible Problems
A major challenge often overlooked in research on nonlinear optimization is the fact that contemporary techniques often perform poorly when all of the problem constraints cannot be satisfied simultaneously. Users of optimization methods and software intend to formulate feasible models, but with the growing complexity of models attempted to be solved today, the potential infeasibility of problem instances is unavoidable. (This is especially true, e.g., in the context of mixed-integer nonlinear optimization algorithms that must solve sequences of related nonlinear optimization subproblems, many of which may be infeasible due to the addition of constraints imposed on the integer variables.) Many contemporary algorithms have theoretical convergence guarantees when no feasible solution exists, but practical experience has shown that in many situations this convergence can be extremely slow. Thus, if a user formulates their problem, gives it to an optimization solver, and the solver spends an unacceptable amount of time without yielding any useful results, the cause of this poor performance may not even be clear. Is the problem, as posed, feasible? highly nonlinear? degenerate? some or all of the above?
Extreme nonlinearity and constraint degeneracy are problem features that are commonly to blame for the failure of nonlinear optimization algorithms. However, in the face of both of these features, the goal of an optimization algorithm remains clear: minimize the objective function subject to satisfying the constraints. What is most interesting about problem infeasibility, on the other hand, is that it puts into question what exactly a user should request from the solver. Surely, the solver should detect infeasibility rapidly, but is a report that their model is infeasible sufficient to satisfy the user’s needs? If the “level” of infeasibility is relatively minor, then the user may desire to minimize their objective subject to some minor violations in satisfying their constraints. On the other hand, if the level of infeasibility is more severe, then the user may desire information about constraints that, if removed or modified, would reveal feasible solutions.
Considering a measure of infeasibility such as
$$v(x) := \|e(x)\|_1 + \|\max\{c(x),0\}\|_1,$$
contemporary optimization methods often, at best, switch from solving the given optimization problem to minimizing a measure such as \(v\) when the constraints may be infeasible. One of the thrusts in my research on this topic has been to enhance existing approaches in order to detect infeasibility in this manner much more rapidly than is commonly done in contemporary methods. The key idea in this work is to carefully monitor progress toward constraint satisfaction, and to rapidly transition to minimizing constraint violation when consistent progress is not being made. The challenge, of course, is to accomplish this without being too conservative; i.e., one wishes to avoid transitioning to only minimizing \(v\) when the given optimization problem is actually feasible.
In on-going work on this topic, I am exploring methods for handling infeasibility in a more robust manner. That is, rather than transitioning to only minimizing a measure such as \(v\) above, an optimization solver would ideally transition to solving, for some \(\epsilon>0\), the following problem:
$$\min_{x\in\mathbb{R}^n}\ f(x)\ \ \text{s.t.}\ \ v(x) \leq \epsilon.$$
(Clearly, other—perhaps weighted—norms on the constraint violation could be considered here, in some cases perhaps to distinguish between “hard” and “soft” constraints.) This idea of minimizing an objective function subject to controlled violations in the constraints is surprisingly not widely explored in the nonlinear optimization research community, despite the significant impact that reliable methods for solving such problems could have in a variety of settings.